Denormalizing Data
Data denormalization is a technique in ClickHouse to use flattened tables to help minimize query latency by avoiding joins.
Comparing Normalized vs. Denormalized Schemas
Denormalizing data involves intentionally reversing the normalization process to optimize database performance for specific query patterns. In normalized databases, data is split into multiple related tables to minimize redundancy and ensure data integrity. Denormalization reintroduces redundancy by combining tables, duplicating data, and incorporating calculated fields into either a single table or fewer tables - effectively moving any joins from query to insert time.
This process reduces the need for complex joins at query time and can significantly speed up read operations, making it ideal for applications with heavy read requirements and complex queries. However, it can increase the complexity of write operations and maintenance, as any changes to the duplicated data must be propagated across all instances to maintain consistency.

A common technique popularized by NoSQL solutions is to denormalize data in the absence of JOIN support, effectively storing all statistics or related rows on a parent row as columns and nested objects. For example, in an example schema for a blog, we can store all Comments as an Array of objects on their respective posts.
When to use denormalization
In general, we would recommend denormalizing in the following cases:
- Denormalize tables which change infrequently or for which a delay before data is available for analytical queries can be tolerated i.e. the data can be completely reloaded in a batch.
- Avoid denormalizing many-to-many relationships. This can result in the need to update many rows if a single source row changes.
- Avoid denormalizing high cardinality relationships. If each row in a table has thousands of related entries in another table, these will need to be represented as an
Array- either of a primitive type or tuples. Generally, arrays with more than 1000 tuples would not be recommended. - Rather than denormalizing all columns as nested objects, consider denormalizing just a statistic using materialized views (see below).
All information doesn't need to be denormalized - just the key information that needs to be frequently accessed.
The denormalization work can be handled in either ClickHouse or upstream e.g. using Apache Flink.
Avoid denormalization on frequently updated data
For ClickHouse, denormalization is one of several options users can use in order to optimize query performance but should be used carefully. If data is updated frequently and needs to be updated in near-real time, this approach should be avoided. Use this if the main table is largely append only or can be reloaded periodically as a batch e.g. daily.
As an approach it suffers from one principal challenge - write performance and updating data. More specifically, denormalization effectively shifts the responsibility of the data join from query time to ingestion time. While this can significantly improve query performance, it complicates ingestion and means that data pipelines need to re-insert a row into ClickHouse should any of the rows which were used to compose it change. This can mean that a change in one source row potentially means many rows in ClickHouse need to be updated. In complicated schemas, where rows have been composed from complex joins, a single row change in a nested component of a join can potentially mean millions of rows need to be updated.
Achieving this in real-time is often unrealistic and requires significant engineering, due to two challenges:
- Triggering the correct join statements when a table row changes. This should ideally not cause all objects for the join to be updated - rather just those that have been impacted. Modifying the joins to filter to the correct rows efficiently, and achieving this under high throughput, requires external tooling or engineering.
- Row updates in ClickHouse need to be carefully managed, introducing additional complexity.
A batch update process is thus more common, where all of the denormalized objects are periodically reloaded.
Practical cases for denormalization
Let's consider a few practical examples where denormalizing might make sense, and others where alternative approaches are more desirable.
Consider a Posts table that has already been denormalized with statistics such as AnswerCount and CommentCount - the source data is provided in this form. In reality, we may want to actually normalize this information as it's likely to be subject to be frequently changed. Many of these columns are also available through other tables e.g. comments for a post are available via the PostId column and Comments table. For the purposes of example, we assume posts are reloaded in a batch process.
We also only consider denormalizing other tables onto Posts, as we consider this our main table for analytics. Denormalizing in the other direction would also be appropriate for some queries, with the same above considerations applying.
For each of the following examples, assume a query exists which requires both tables to be used in a join.
Posts and Votes
Votes for posts are represented as separate tables. The optimized schema for this is shown below as well as the insert command to load the data:
CREATE TABLE votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId)
INSERT INTO votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 26.272 sec. Processed 238.98 million rows, 2.13 GB (9.10 million rows/s., 80.97 MB/s.)
At a first glance, these might be candidates for denormalizing on the posts table. There are a few challenges to this approach.
Votes are added frequently to posts. While this might diminish per post over time, the following query shows that we have around 40k votes per hour over 30k posts.
SELECT round(avg(c)) AS avg_votes_per_hr, round(avg(posts)) AS avg_posts_per_hr
FROM
(
SELECT
toStartOfHour(CreationDate) AS hr,
count() AS c,
uniq(PostId) AS posts
FROM votes
GROUP BY hr
)
┌─avg_votes_per_hr─┬─avg_posts_per_hr─┐
│ 41759 │ 33322 │
└──────────────────┴──────────────────┘
This could be addressed by batching if a delay can be tolerated, but this still requires us to handle updates unless we periodically reload all posts (unlikely to be desirable).
More troublesome is some posts have an extremely high number of votes:
SELECT PostId, concat('https://stackoverflow.com/questions/', PostId) AS url, count() AS c
FROM votes
GROUP BY PostId
ORDER BY c DESC
LIMIT 5
┌───PostId─┬─url──────────────────────────────────────────┬─────c─┐
│ 11227902 │ https://stackoverflow.com/questions/11227902 │ 35123 │
│ 927386 │ https://stackoverflow.com/questions/927386 │ 29090 │
│ 11227809 │ https://stackoverflow.com/questions/11227809 │ 27475 │
│ 927358 │ https://stackoverflow.com/questions/927358 │ 26409 │
│ 2003515 │ https://stackoverflow.com/questions/2003515 │ 25899 │
└──────────┴──────────────────────────────────────────────┴───────┘
The main observation here is that aggregated vote statistics for each post would be sufficient for most analysis - we do not need to denormalize all of the vote information. For example, the current Score column represents such a statistic i.e. total up votes minus down votes. Ideally, we would just be able to retrieve these statistics at query time with a simple lookup (see dictionaries).
Users and Badges
Now let's consider our Users and Badges:
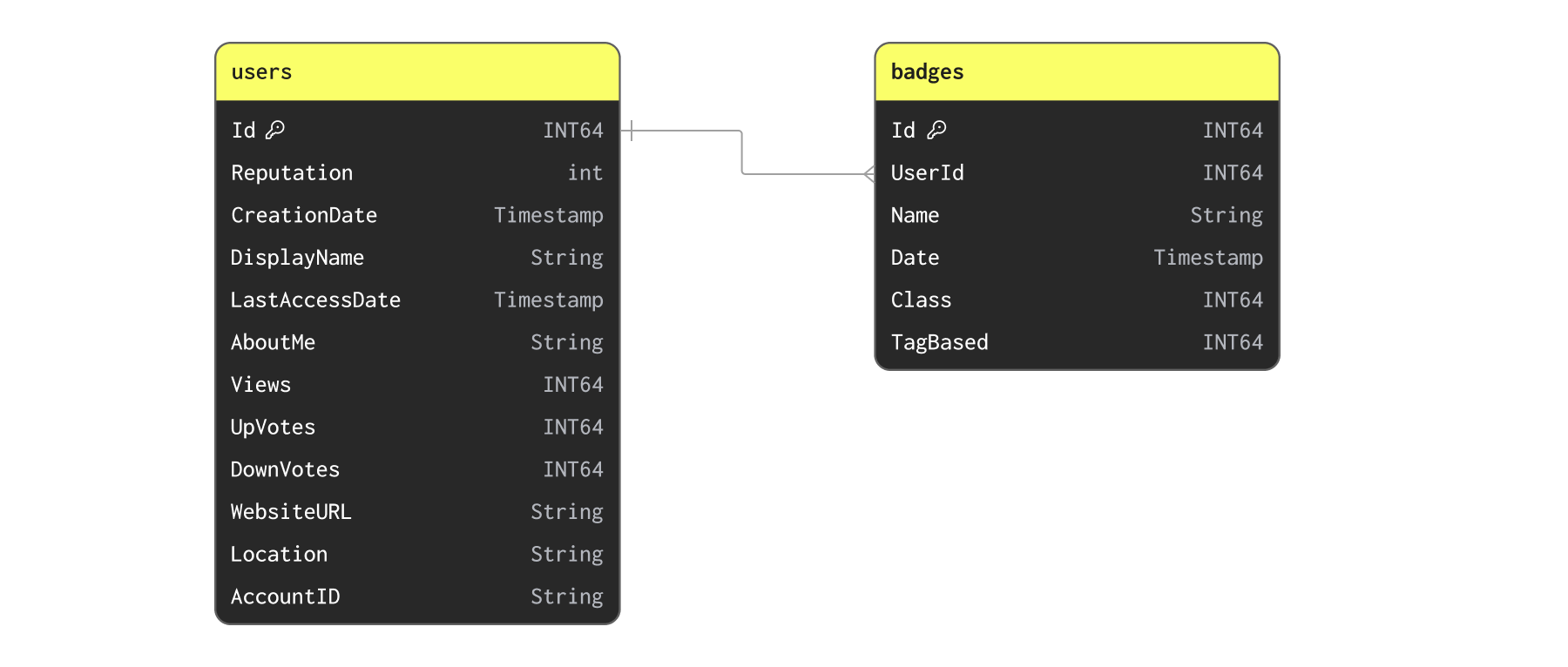 We first insert the data with the following command:
We first insert the data with the following command:CREATE TABLE users
(
`Id` Int32,
`Reputation` LowCardinality(String),
`CreationDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`DisplayName` String,
`LastAccessDate` DateTime64(3, 'UTC'),
`AboutMe` String,
`Views` UInt32,
`UpVotes` UInt32,
`DownVotes` UInt32,
`WebsiteUrl` String,
`Location` LowCardinality(String),
`AccountId` Int32
)
ENGINE = MergeTree
ORDER BY (Id, CreationDate)
CREATE TABLE badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
INSERT INTO users SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/users.parquet')
0 rows in set. Elapsed: 26.229 sec. Processed 22.48 million rows, 1.36 GB (857.21 thousand rows/s., 51.99 MB/s.)
INSERT INTO badges SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 18.126 sec. Processed 51.29 million rows, 797.05 MB (2.83 million rows/s., 43.97 MB/s.)
While users may acquire badges frequently, this is unlikely to be a dataset we need to update more than daily. The relationship between badges and users are one-to-many. Maybe we can simply denormalize badges onto users as a list of tuples? While possible, a quick check to confirm the highest number of badges per user suggests this isn't ideal:
SELECT UserId, count() AS c FROM badges GROUP BY UserId ORDER BY c DESC LIMIT 5
┌─UserId─┬─────c─┐
│ 22656 │ 19334 │
│ 6309 │ 10516 │
│ 100297 │ 7848 │
│ 157882 │ 7574 │
│ 29407 │ 6512 │
└────────┴───────┘
It's probably not realistic to denormalize 19k objects onto a single row. This relationship may be best left as separate tables or with statistics added.
We may wish to denormalize statistics from badges on to users e.g. the number of badges. We consider such an example when using dictionaries for this dataset at insert time.
Posts and PostLinks
PostLinks connect Posts which users consider to be related or duplicated. The following query shows the schema and load command:
CREATE TABLE postlinks
(
`Id` UInt64,
`CreationDate` DateTime64(3, 'UTC'),
`PostId` Int32,
`RelatedPostId` Int32,
`LinkTypeId` Enum('Linked' = 1, 'Duplicate' = 3)
)
ENGINE = MergeTree
ORDER BY (PostId, RelatedPostId)
INSERT INTO postlinks SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/postlinks.parquet')
0 rows in set. Elapsed: 4.726 sec. Processed 6.55 million rows, 129.70 MB (1.39 million rows/s., 27.44 MB/s.)
We can confirm that no posts have an excessive number of links preventing denormalization:
SELECT PostId, count() AS c
FROM postlinks
GROUP BY PostId
ORDER BY c DESC LIMIT 5
┌───PostId─┬───c─┐
│ 22937618 │ 125 │
│ 9549780 │ 120 │
│ 3737139 │ 109 │
│ 18050071 │ 103 │
│ 25889234 │ 82 │
└──────────┴─────┘
Likewise, these links are not events which occur overly frequently:
SELECT
round(avg(c)) AS avg_votes_per_hr,
round(avg(posts)) AS avg_posts_per_hr
FROM
(
SELECT
toStartOfHour(CreationDate) AS hr,
count() AS c,
uniq(PostId) AS posts
FROM postlinks
GROUP BY hr
)
┌─avg_votes_per_hr─┬─avg_posts_per_hr─┐
│ 54 │ 44 │
└──────────────────┴──────────────────┘
We use this as our denormalization example below.
Simple statistic example
In most cases, denormalization requires the adding of a single column or statistic onto a parent row. For example, we may just wish to enrich our posts with the number of duplicate posts and we simply need to add a column.
CREATE TABLE posts_with_duplicate_count
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
... -other columns
`DuplicatePosts` UInt16
) ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
To populate this table, we utilize an INSERT INTO SELECT joining our duplicate statistic with our posts.
INSERT INTO posts_with_duplicate_count SELECT
posts.*,
DuplicatePosts
FROM posts AS posts
LEFT JOIN
(
SELECT PostId, countIf(LinkTypeId = 'Duplicate') AS DuplicatePosts
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts.Id = postlinks.PostId
Exploiting complex types for one-to-many relationships
In order to perform denormalization, we often need to exploit complex types. If a one-to-one relationship is being denormalized, with a low number of columns, users can simply add these as rows with their original types as shown above. However, this is often undesirable for larger objects and not possible for one-to-many relationships.
In cases of complex objects or one-to-many relationships, users can use:
- Named Tuples - These allow a related structure to be represented as a set of columns.
- Array(Tuple) or Nested - An array of named tuples, also known as Nested, with each entry representing an object. Applicable to one-to-many relationships.
As an example, we demonstrate denormalizing PostLinks on to Posts below.
Each post can contain a number of links to other posts as shown in the PostLinks schema earlier. As a Nested type, we might represent these linked and duplicates posts as follows:
SET flatten_nested=0
CREATE TABLE posts_with_links
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
... -other columns
`LinkedPosts` Nested(CreationDate DateTime64(3, 'UTC'), PostId Int32),
`DuplicatePosts` Nested(CreationDate DateTime64(3, 'UTC'), PostId Int32),
) ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
Note the use of the setting
flatten_nested=0. We recommend disabling the flattening of nested data.
We can perform this denormalization using an INSERT INTO SELECT with an OUTER JOIN query:
INSERT INTO posts_with_links
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts.Id = postlinks.PostId
0 rows in set. Elapsed: 155.372 sec. Processed 66.37 million rows, 76.33 GB (427.18 thousand rows/s., 491.25 MB/s.)
Peak memory usage: 6.98 GiB.
Note the timing here. We've managed to denormalize 66m rows in around 2mins. As we'll see later, this is an operation we can schedule.
Note the use of the groupArray functions to collapse the PostLinks down into an array for each PostId, prior to joining. This array is then filtered into two sublists: LinkedPosts and DuplicatePosts, which also exclude any empty results from the outer join.
We can select some rows to see our new denormalized structure:
SELECT LinkedPosts, DuplicatePosts
FROM posts_with_links
WHERE (length(LinkedPosts) > 2) AND (length(DuplicatePosts) > 0)
LIMIT 1
FORMAT Vertical
Row 1:
──────
LinkedPosts: [('2017-04-11 11:53:09.583',3404508),('2017-04-11 11:49:07.680',3922739),('2017-04-11 11:48:33.353',33058004)]
DuplicatePosts: [('2017-04-11 12:18:37.260',3922739),('2017-04-11 12:18:37.260',33058004)]
Orchestrating and scheduling denormalization
Batch
Exploiting denormalization requires a transformation process in which it can be performed and orchestrated.
We have shown above how ClickHouse can be used to perform this transformation once data has been loaded through an INSERT INTO SELECT. This is appropriate for periodic batch transformations.
Users have several options for orchestrating this in ClickHouse, assuming a periodic batch load process is acceptable:
- External tooling - Utilizing tools such as dbt and Airflow to periodically schedule the transformation. The ClickHouse integration for dbt ensures this is performed atomically with a new version of the target table created and then atomically swapped with the version receiving queries (via the EXCHANGE command).
- Refreshable Materialized Views (experimental) - Refreshable materialized views can be used to periodically schedule a query with the results sent to a target table. On query execution, the view ensures the target table is atomically updated. This provides a ClickHouse native means of scheduling this work.
Streaming
Users may alternatively wish to perform this outside of ClickHouse, prior to insertion, using streaming technologies such as Apache Flink. Alternatively, incremental materialized views can be used to perform this process as data is inserted.